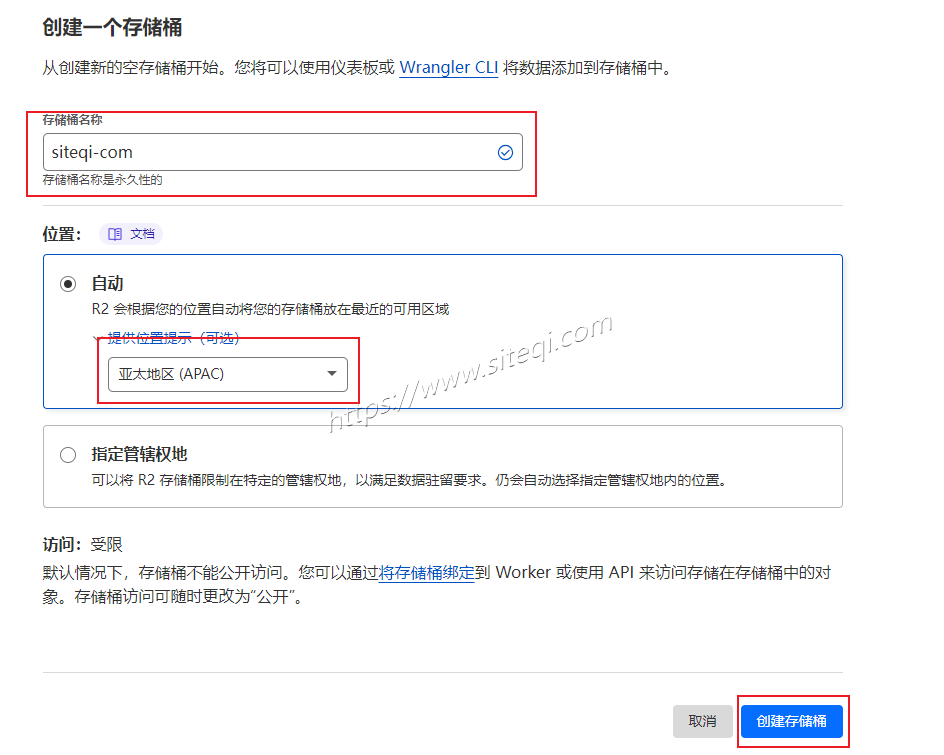
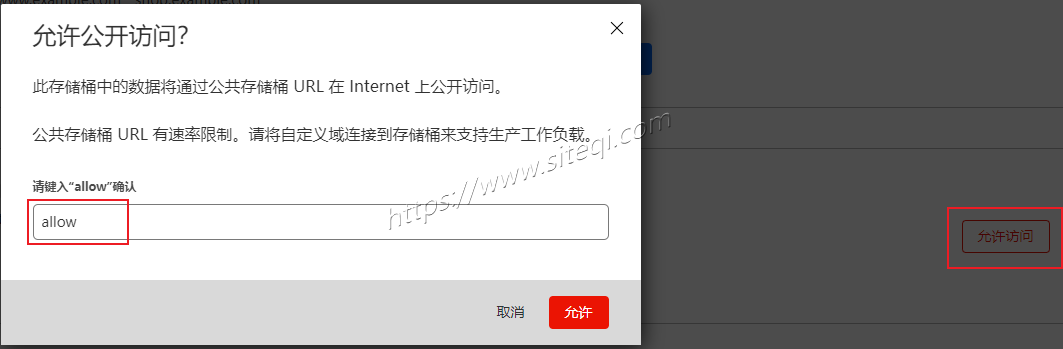
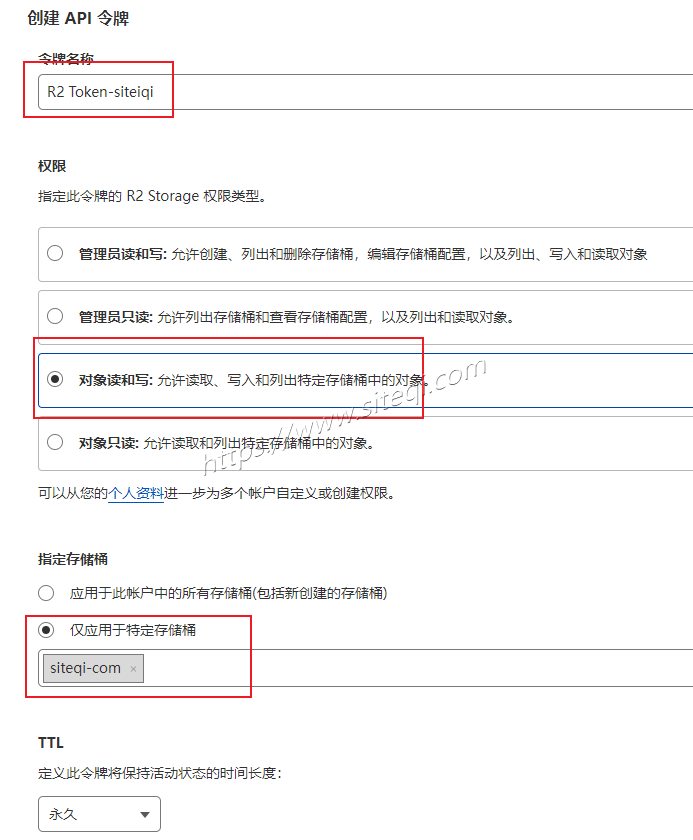
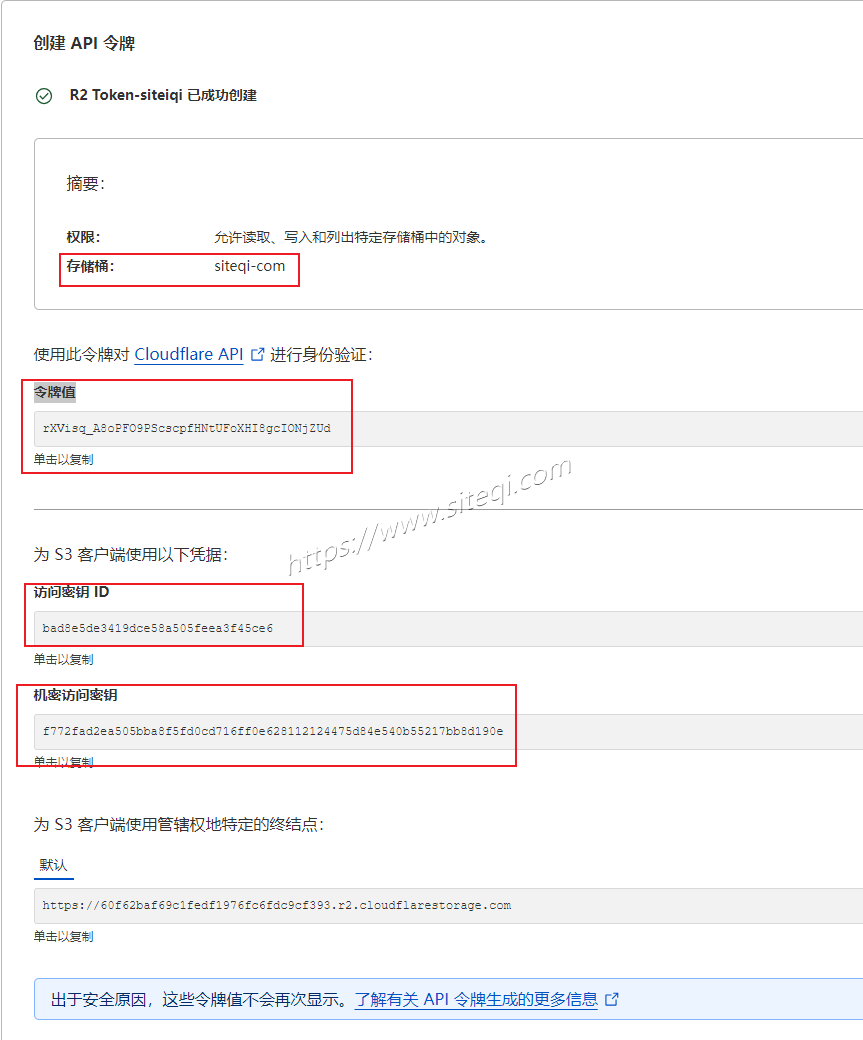
家庭数据中心系列 cloudflare教程(六) CF Cache Rules(缓存规则)功能介绍及详细配置教程
Contents [hide]
前言
在已经完成的CF系列教程"一"到"五"中,除了"一"到"三"的筑基三部曲之外,后续的"四"和"五"我分别介绍了CF WAF和CF DDoS防护,因为我认为这2个功能是CF流量序列中最有价值的2个重点功能,值得我用单独的篇幅来详细介绍。
但是,由于每个人实际环境以及需求各不相同,CF流量序列中还有很多其他功能,对于需要的人来说都可以说是有价值的重点功能,比如Cache Rules。
其实,Cache Rules提供的CDN功能本来才应该是CF最受欢迎的功能,只是,由于国内网络环境的特殊性,导致Free计划的用户使用了CF的CDN之后,不管是访问者被分配的访问地址还是回源请求发起的地点,大概率被分配到美国的CF数据中心(以美西的圣何塞数据中心最多),这导致访问者体验大概率还不如不使用CF CDN直接访问来得快(毕竟往返都要跨太平洋),所以才有对国内访问”负优化”之称。
不过,除了国内的访问者以及某几个相似的特殊国家之外,全球其他地区的访问体验还是不错的,所以CF的CDN功能还是有必要配置(特别是对于那些战略着眼于全球而非仅仅是国内的人而言)。
另外,对于某些内容(比如图床的图片)而言,慢那么一点其实感知也并不明显,所以,CF的Cache Rules的确也是重要且最有价值的功能之一。
Cache Rules(缓存规则)
Cache Rules介绍
默认情况下(未配置任何缓存规则时),CF只会对部分扩展名的静态资源生效(TTL一般都为2小时),这些静态资源包括但不限于:
- 图像文件:
.jpg, .jpeg, .png, .gif, .ico, .svg 等 - 字体文件:
.woff, .woff2, .ttf, .otf, .eot 等 - CSS文件:
.css - JavaScript文件:
.js - 多媒体文件:
.mp3, .mp4, .avi, .mkv, .webm, .ogg 等 - 文档文件:
.pdf, .doc 等
这样是非常不方便的,我可能有其他正常的需求,比如:
- 我不想缓存.mkv扩展名的视频文件,因为我网站上这格式的视频文件很多且都很大,如果缓存并且访问量还大的话,很可能导致我被CF封号
- 我想缓存HTML文件,但是默认的静态资源里并不包括HTML
- 默认的2小时太短,我想缓存更长时间
- ……..
诸如以上的自定义需求太多也太普遍,为了解决用户这些正常及普遍的对缓存的自定义需求,CF推出了Cache Rules。
CF的Cache Rules功能允许用户根据特定的条件和需求自定义缓存行为,从而控制CDN、浏览器缓存的内容和生效时间,进而达到优化网站内容的加载速度和缓存效率的效果。
Cache Rules的主要功能和特点如下:
- 灵活的缓存控制:用户可以设置规则来定义哪些内容应被缓存,哪些内容不应缓存。例如,可以指定特定路径、请求头、查询参数等,以控制缓存行为。
- 支持复杂条件:Cache Rules支持基于URL路径、HTTP头、查询参数等多种条件进行匹配,用户可以创建复杂的缓存策略,如缓存特定文件类型、基于地域的缓存策略等。
- 优先级管理:用户可以为不同的缓存规则设置优先级,确保高优先级的规则在缓存控制中被优先执行,帮助实现更精确的缓存管理。
- 动态和静态内容的区分:用户可以根据内容类型(静态或动态)设置不同的缓存策略,优化缓存命中率和服务器负载。
- 实时生效和调试:规则更改后可以实时生效,用户可以通过Cloudflare的仪表板或API进行管理和调试,方便快速调整和测试缓存策略。
- 集成其他Cloudflare服务:Cache Rules与Cloudflare的其他服务(如WAF、Rate Limiting、Argo Smart Routing等)集成,提供更加全面的安全和性能优化功能。
Cache Rules上手指南
Cache Rules规则构成
一条Cache Rules的规则有2部分内容组成,请求传入匹配和缓存资格。
请求传入匹配
允许用户设置传入请求匹配的特定条件,以此作为后续是否进行缓存的前置判定。
常用的匹配条件有如下几种:
- URL路径
• 基于URL路径的匹配,如特定的文件夹或文件扩展名。
• 支持通配符和正则表达式匹配。 - 主机名
• 根据请求的主机名进行匹配。 - 查询参数
• 根据请求的查询参数进行匹配,允许对带有特定参数的请求进行缓存控制。 - HTTP请求方法
• 根据GET、POST等HTTP请求方法进行匹配。 - HTTP请求头
• 基于特定的请求头进行匹配,如User-Agent、Accept-Language等。 - Cookie
• 根据请求中包含的特定Cookie进行匹配。
其他可选的判断条件还有:引用方、SSL/HTTPS、用户代理、X_Forwarded_For等。
缓存资格
对满足设置的传入请求匹配的访问流选择是绕过缓存还是进行缓存,有如下2种选择:
- 绕过缓存
• 让CF不要缓存源服务器对满足请求传入匹配的访问请求的响应内容,通常用在访问请求对动态内容或者需要登录访问的内容的访问。
• 唯一的可选项只有浏览器TTL

- 符合缓存条件
• 让CF缓存源服务器对满足请求传入匹配的访问请求的响应内容,通常用在访问请求对静态内容的访问。
• 有6个可选项,其中,以边缘TTL和浏览器TTL最常用,本文中就以这2个选项为例进行演示:

注:边缘TTL指静态内容在CF边缘缓存中的存在时间,浏览器TTL指静态内容在浏览器本地的缓存中的存在时间,一般来说,为了页面内容显示的一致性,浏览器TTL的时间应该小于边缘TTL。
Cache Rules配置逻辑
Free计划中,Cache Rules有10条的额度,足够一般人使用了,不过,在配置逻辑上,有几点要注意。
1、规则序号越小优先级越高,所以需要梳理好缓存规则的逻辑顺序,将优先级高的排在前面,一般是需要绕过缓存的在前,如下图:

2、动态网站的非动态内容部分也可以缓存,不过需要在优先级较高的绕过缓存部分的规则中先排除掉动态内容部分。
3、流量序列中,Cache Rules的优先级较高,所以如果需要访问请求被流量序列中优先级较低的节点功能处理(例如Workers),对于缓存规则而言,需要保证访问请求命中缓存规则的”绕过缓存”,而不是命中”符合缓存条件”。
4、如果托管二级域名下有多个子域名网站,并且动态、静态内容都有,那么创建缓存规则的时候,最好能加上主机名作为限制条件,避免缓存逻辑不清不楚。
Cache Rules配置示例
静态网站
以我群站导航页网址www.tangwudi.com为例,假设采用的图床网址为image.tangwudi.com,采用的API路径为www.tangwudi.com/api*,按照前面说的缓存规则的配置逻辑,应该如下设置:
1、API属于动态内容,需要绕过缓存

2、对于图床的图片进行缓存


注:边缘TTL和浏览器TTL为可选项,默认不设置均为2小时。对于图片之类的静态内容,是否设置TTL或者设置多长时间需要看网站的类型而定,主要是看图片更新的频率。对于我的群站导航首页而言,图片基本不会动,所以完全可以有多长设置多长,比如边缘TTL直接设置1年也没毛病,至于浏览器TTL,理论上设置1年也可以,但是没必要,保险起见1个月就差不多了,静态个人博客类型的网站也是一样的道理。
3、其他静态内容的缓存(主要是HTML)

边缘TTL和浏览器TTL和图片缓存一样:

最终完成效果:

注1:图片缓存和HTML缓存在此例中的TTL(边缘TTL和浏览器TTL)是一样的,理论上可以将2条规则合为一条,但是,这只是由于此例的特殊性,一般来说,图片缓存的TTL和HTML的TTL一样的可能性并不大,所以分开用2条”符合缓存条件”的规则是合理的。不同TTL的缓存内容需要用不同的规则来设置,至于最终需要多少条缓存规则,则由网站内容在缓存控制方面的精细程度决定。
注2:请根据实际环境将主机名”blog.tangwudi.com“替换为自己的实际主机名。
动态网站
我的博客是使用wordpress搭建,也算是动态博客类型的代表,所以就以我的博客网址blog.tangwudi.com为例,本例中假定图片是上传到wordpress自身的媒体库中,未使用外部图床。由于wordpress站点的动态内容有其特点,例如特定URI( “/wp-admin”、”/wp-login”、”/wp-comment”等开头的内容)以及包含特定cookie字段(wp-、logged_in、wordpress、comment_、woocommerce_)的请求均不能缓存,所以为了保证准确性,采用分层规则匹配的方式,配置建议规则如下:
1、绕过访问链接中包含动态内容的特殊URI(从URI层面匹配)的访问请求的缓存
注意规则的运算符,URI路径的的运算符我这里均为”包含”(这个是为了偷懒,当然也可以选择运算符”开头为”,那么后面就要按格式写,比如”开头为”后面是”/wp-admin”):

表达式为:
(http.host eq "blog.tangwudi.com" and http.request.uri.path contains "wp-admin") or (http.host eq "blog.tangwudi.com" and http.request.uri.path contains "wp-login") or (http.host eq "blog.tangwudi.com" and http.request.uri.path contains "wp-comment") or (http.host eq "blog.tangwudi.com" and http.request.uri.path contains "?s=") or (http.host eq "blog.tangwudi.com" and http.request.uri.path contains "xmlrpc") or (http.host eq "blog.tangwudi.com" and http.request.uri.path contains "preview=true")
2、绕过访问wordpress时cookie内包含特定字符的访问请求的缓存
注意每条规则中”Cookie”的运算符均为包含:

表达式为:
(http.host eq "blog.tangwudi.com" and http.cookie contains "_logged_in_") or (http.host eq "blog.tangwudi.com" and http.cookie contains "wordpress") or (http.host eq "blog.tangwudi.com" and http.cookie contains "comment_") or (http.host eq "blog.tangwudi.com" and http.cookie contains "woocommerce_")
3、绕过以.php结尾的页面

注:其实上面2条规则已经可以足以涵盖动态内容了,这条只能算是打个补丁。
4、缓存图片内容

注:这部分的边缘TTL以及浏览器TTL的设置参考文章前面部分描述。
5、缓存HTML

表达式:
(http.host eq "blog.tangwudi.com" and ends_with(http.request.uri.path, ".html") and not http.cookie contains "_logged_in_" and not http.cookie contains "wordpress" and not http.cookie contains "comment_" and not http.cookie contains "woocommerce_") or (http.host eq "blog.tangwudi.com" and ends_with(http.request.uri.path, ".htm") and not http.cookie contains "_logged_in_" and not http.cookie contains "wordpress" and not http.cookie contains "comment_" and not http.cookie contains "woocommerce_")
注:这部分的边缘TTL以及浏览器TTL的设置参考文章前面部分描述。
6、缓存其他内容

这里主要是针对除了HTML以外的其他内容,比如css文件等。
注:这部分的边缘TTL以及浏览器TTL的设置参考文章前面部分描述。
最终配置如下:

注1:其实第4,5,6条规则粗旷点可以只保留第6条,4,5都可以直接删除,效果是一样的,但是之所以分开还是为了降低风险以及让边缘TTL及浏览器TTL可以根据不同类型的缓存设置各自适合的值。
注2:其实绕过缓存规则的URI部分和cookie部分是相互覆盖的关系,由于我对wordpress的细节不够了解,为了保险写成2条,主打一个保险。其实肯定有较多的重复规则,比如绕过cookie部分_logged_in_和wordpress这两条就有点重复了,不过我看一些资料里一会说wordpress_logged_in,一会说wp_loggen_in,我也懒得去深究了,干脆2个都写上去,最多重复,但是保险。
注3:使用wordpress建站的类型多种多样,不同类型站点的动态内容可能有自己特有的URI或者特有的cookie值,所以大家可能需要根据自己站点特点修改URI部分和cookie部分的内容。
注4:虽然上面的配置是以wordpress为例,但是其他动态博客配置思路是一样的,根据实际情况修改下就行了。
注5:请根据实际环境将主机名”blog.tangwudi.com“替换为自己的实际主机名。
另:除了Cache Rules以外,还有另一个能设置CF缓存行为的功能项就是”页面规则”,且页面规则在流量序列中的处理优先级是高于Cache Rules的:

不过,一般不建议使用”页面规则”来进行缓存,有以下几点原因:
1、页面规则只有3条额度(Free计划),太少了,而且页面规则除了缓存功能以外,还可以实现很多其他的功能,如下:



所以页面规则应该用来实现更加复杂的复合型需求,或者某些需要更高优先级处理的特殊流量的临时处理上,仅仅用来实现Cache Rules都能完成的功能就太浪费了(毕竟Cache Rules有10条的额度,比页面规则的3条宽松多了~)。
2、页面规则的匹配条件只能用URL,太简陋了:

不像Cache Rules的”请求传入匹配”支持多种条件以及or和and的组合。
3、边缘TTL最长只能一个月,Cache Rules可以设置为1年:

4、其实还有个原因就是不清除CF未来的态度,因为6月左右的时候,页面规则其实已经公告被废除,不过不知道后来怎么又收回了废除的通知,搞不清除以后会咋样,所以能不用就不用吧,就算要用也尽量用在临时性处理上,平时尽量使用流量序列上已有的节点功能来完成吧,这个最保险。
“缓存”部分的其他可选项
在”缓存”部分,有几个选项大家可以根据自己的需要进行配置。
清除缓存

清除缓存文件用来强制CF从您的 Web 服务器中提取这些文件的最新版本。
可以选择”自定义清除”以清除特定的URL(Free计划只能清除完整匹配URL的资源,不支持*通配符):

也可以选择”清除所有内容”:

缓存级别

缓存级别决定CF应缓存多少网站的静态内容,CF的 CDN 根据以下级别缓存静态内容:
- 没有查询字符串
当没有查询字符串时,从缓存中交付资源。 示例 URL:tangwudi.com/pic.jpg - 忽略查询字符串
向每个人提供相同的资源,与查询字符串无关。 示例 URL:tangwudi.com/pic.jpg?ignore=this-query-string - 标准(默认)
每次改变查询字符串时都提供不同的资源。 示例 URL:tangwudi.com/pic.jpg?with=query
除非有特殊要求,否则保持默认的”标准”即可。
浏览器TTL

这个其实就是默认的浏览器TTL值,如果访问请求没有匹配缓存相关规则中设置的浏览器TTL值,或者源服务器设置的浏览器TTL值小于该值,就会使用此处的值,这个大家根据自己的需要设置即可。
Crawler Hints(爬虫提示)

仔细研究了一下,发现这个功能比较有意思:当托管在CF上的网站内容发生变化的时候,该功能会记录这些变化,然后向搜索引擎和其他合法爬虫程序提供有关内容变化频率和重要性的提示,帮助爬虫程序更智能地安排抓取计划,优先抓取变化频繁或重要的内容,确保搜索引擎索引的信息是最新的,也因为爬取效率提高,减少了对源站不必要的抓取,间接降低了源站服务器的负载。
另:怎么感觉如果博客园当初使用CF并开启了这个功能,百度蜘蛛爬虫就不会把博客园爬得崩溃了?
该功能默认关闭,没什么危险性,可以保持开启。
Always Online™

简单来说,就是当源站出现故障的时候,如果用户访问链接页面的内容在缓存中,CF就会直接把这个内容返回给用户,并且在页面顶部显示一条信息提示:源站出问题了,这个只是缓存内容。
关键问题在于这个功能主要是对能缓存的静态内容有效,动态内容和交互式功能(如用户登录、购物车等)在源服务器不可用时就无法正常工作。所以这个功能对于静态类型的网站很好用,但是对于动态类型的网站就只能说聊胜于无了(我遇到过,wordpress源站出问题时,有些页面能打开,不过看起来布局、颜色也不太正常,所以只能说聊胜于无)。
该功能没啥危险性,可以保持开启。
开发模式

该模式开启后,所有请求都绕过CF的缓存,直接传递到源服务器。此功能在需要即时查看所做更改时非常有用。启用后,如果未手动关闭,开发模式将持续三个小时,然后自动关闭。
Tiered Cache

简单来说,如果不启用该功能,那么CF全球任何一个数据中心都可以直接向源服务器发起回源请求,哪怕这个数据中心离源服务器很远。
而启用该功能之后,CF会将全球数据中心分为上下2层,然后使用 Argo 性能和路由数据为源服务器动态查找单个最佳上层(最佳上层离源服务器最近,理论上回源效率最高),只有上层才能向源服务器发起回源请求,而下层只能向上层查询。
该功能没有危险性,可以保持开启。
如何验证缓存状态
静态站点的验证
一般的静态类型的网站(以www.tangwudi.com为例)验证缓存状态,可以按照如下流程进行验证。
打开chrome浏览器(或者edge),按”F12″进入开发者工具,点击”网络”选项卡,类型选择”全部”:

在浏览器地址栏输入
www.tangwudi.com并回车,然后在”重新加载”按钮上点右键并选择”清空缓存并硬性重新加载”:
在左边名称处选择
www.tangwudi.com,在右边”标头”部分的”响应标头”的”cf-cache-status”可以查看缓存是否成功:
动态站点的验证
以我的临时测试站点blog.tangwudi.xyz为例:

注1:一般情况下,如果使用Cache Rules(或者页面规则)控制CDN完成缓存,cf-cache-status通常有3种结果:HIT(完全缓存)、DYNAMIC(部分缓存,一般是没有配置专门的Cache Rules而只是触发了CF默认的缓存规则,或者是动态网站登录后因为cookie里的关键字匹配了”绕过缓存”的策略,所以只是缓存了一部分)、BYPASS(绕过,说明有缓存规则设置绕过了该地址的缓存)。
注2:以上验证方式,只适合通过Cache Rules或者页面规则设置的常规缓存策略实现的缓存效果的验证,不适合使用Workers或者APO方式实现的智能缓存效果的验证,智能缓存效果的验证在后面相关教程中再讲。
注3:对于动态网站(wordpress之类),使用Cache Rules或者页面规则实现的常规缓存效果,类似于灌篮高手里樱木花道的”庶民投篮法”,效果一般,无法蹭到CF企业版用户里的一些高级功能,所以只能说可以凑合着用,而要达到类似于”灌篮”的效果,就要依靠Workers或者APO了,这个留待后续的文章来写。
后话
其实吧,这篇文章我本来是打算”Cache Rules、重定向、页面规则”3个内容一起写的,因为光是Cache Rules的内容我认为没多少可写的内容,几句话就写完了,但是,结果没想到越写越多。。。只能单独用一篇文章来写了。
不过仔细想来,这也是应该的:对于大部分人而言,WAF、DDoS、Cache Rules这3个功能加在一起,已经可以解决最常规的访问和安全方面的问题了,所以,如果教程的一、二、三是”筑基”三部曲的话,那么四、五、六则可以称之为”金丹”三部曲,会用了闯荡江湖已经足以自保了~。